Documentation Day: How the FT.com team improved our documentation to 95% usefulness in 7 hours*
 Friendly runbook trophies up for grabs
Friendly runbook trophies up for grabs
*Plus heaps of preparation and lots of help!
In June a group of FT developers came together for a magical day of sugar and sun fuelled writing in an effort to improve our documentation. By the time we were done we’d improved the quality of the runbooks of our most critical (Platinum tier) systems by 25%, achieved at least 90% ‘usefulness’ on all of them, and shared some hotly contested trophies. We called it ‘Documentation Day 2019’, and I’m going to tell you how we did it.
Platinum tier system: a brand critical system that is required to be available 99.9% of the time and is supported 24⁄7, for example, the FT.com homepage.
Why now?
The drive for improving our documentation was borne of one of our Objective and Key Results measures for 2019 around continuously increasing the maintainability and sustainability of the FT.com and FT App technology stack.
Part of the motivation for this OKR, and our decision to focus first and foremost on our runbooks, was that they were not working effectively for either of their two audiences; the Operations team who provide first line support, and FT.com developers who provide second line support, and this was having a negative effect on both.
First Line Support: a group within the Operations team, working 24⁄7 to support 230 platinum systems at the FT, performing monitoring and basic support tasks for all of them.
Second Line Support: Experts on individual systems (usually developers in the team that built them), called to provide fixes when Ops are unable to.
When something goes wrong with one of our Platinum systems the Ops team try to diagnose the issue and fix it, based on the information in the runbook. However the information in the runbook is often vague, incorrect, or missing entirely, which leaves them unable to perform that function effectively.
When Ops are unable to fix an issue they call the Second Line Support team, that is the developers from the FT.com team that are on the support rota, in order for them to try and fix the issue instead. The problem is that developers on FT.com know that the runbooks don’t provide the correct information for fixing the associated systems and so they, understandably, don’t want to put themselves forward to be on the rota in the first place.
What this has led to is the Ops team being unable to fix issues on FT.com platinum apps and so relying on a small group of expert developers in the FT.com team to provide fixes, who have deep knowledge of the systems but often in their heads.
We hoped that improving runbooks all round would enable Ops support to better diagnose and fix issues, eliminating the need for calling Second Line Support in as many cases as possible, and when Second Line support are called they too have the information they need to fix issues, encouraging confidence in a wider group of FT developers to volunteer to be on the Second Line support rota.
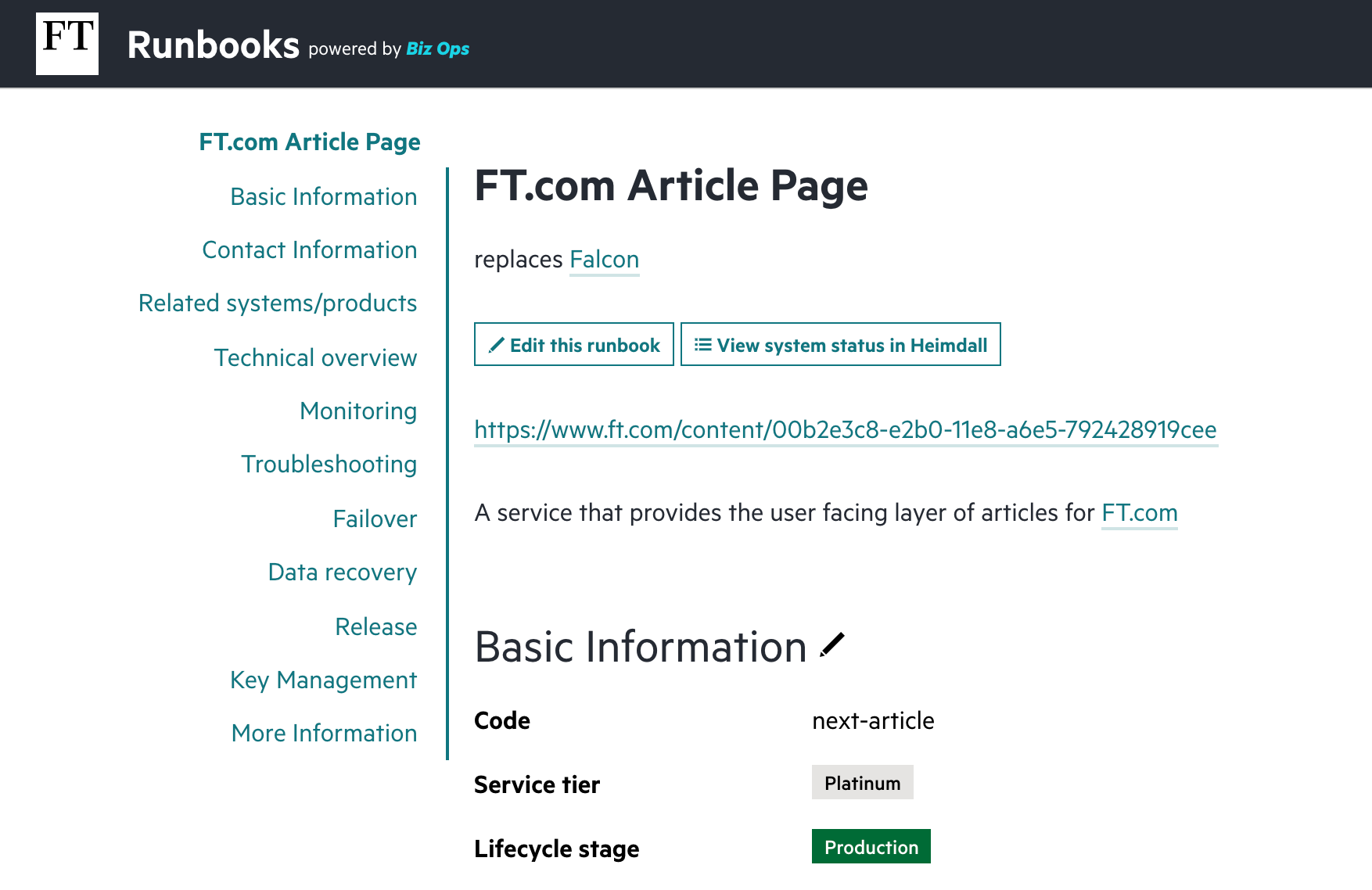 Part of an existing FT.com runbook
Part of an existing FT.com runbook
How?
Conceptually, we knew what we wanted to do: improve our runbooks, but we still had much to decide about how to do it.
To prevent moving effort away from BAU for too long and to provide focus on the issue at hand, we had already agreed that we would attack the problem with the whole group working on runbooks for a single day. Maintaining and updating documentation would be ongoing of course, but this initial push for improvement we would do once.
That decided, we still had three big questions to answer:
How would we know if we had improved our runbooks — what would success look like?
We had a lot of runbooks to improve and one day wasn’t much time — what could we do in advance to make work on the day as effective as possible?
And finally, how was the day going to run? How would we keep the team engaged, help everyone get something from it, ensure people could find the help the needed during the day, and make it fun?
Measuring success
Luckily for us we weren’t the only team at the FT focusing on runbooks in the run up to Documentation Day, and this project came together as a huge collaborative effort between the FT.com team and the Operations and Reliability Team.
The Operations and Reliability team’s focus is on transforming the way we support delivery teams and our products at the FT, by improving the way we execute our monitoring and reliability. As part of their own OKRs they had come up with a metric by which the quality of runbooks could be measured — the System Operability Score (SOS). The System Operability Score deserves a blog post of its own, but for now it’s enough to say that this is what we’d use to quantitively measure success — how much could we improve this score for each runbook?
System Operability Score: a score created to provide tech teams at the FT with clear guidance on what they can do to improve the operability of their systems, with critical issues having a higher negative impact on the score
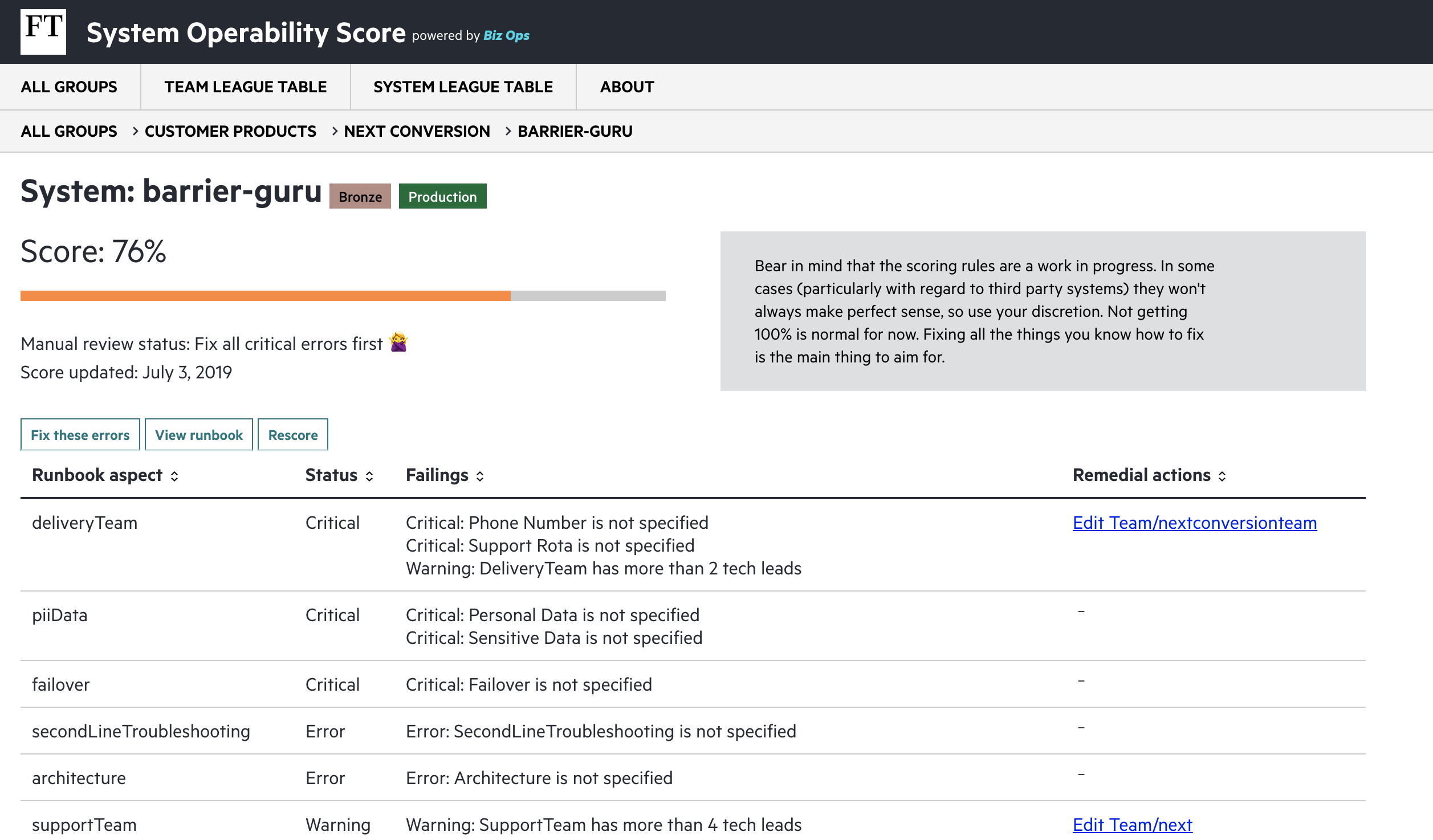 SOS score in action
SOS score in action
This was a great start, but metrics can often be misleading. The score could measure if a field on a runbook was filled it, but there was only a certain extent to which it could validate the data within. We would have to do more than use the score to ensure we reached the level of quality we wanted.
Focusing on the right content
As well as a quantitative measure, we also wanted qualitative feedback, and for this we worked with the First Line Support team — the primary audience for our runbooks. We wanted to understand what a great runbook looked like for them — what sections did they jump to first when there was an issue, and how could the content of these sections be optimised?
We were given invaluable advice by the Ops team, which stemmed from the way their team works: they perform monitoring and basic support tasks for hundreds of Platinum systems at the FT, so they are technically skilled but very broadly. As a result, they need runbooks to be easy to navigate and straightforward to understand. Some key points they asked us to consider were:
Audience — Remember the audience, their technical knowledge will not be as specialised as yours
Language — Keep it simple and unambiguous
Acronyms - Avoid acronyms, or if that’s impossible then** **explain their meaning
Troubleshooting — How can an issue be replicated? Can you provide straightforward instructions for a fix?
Permissions — Do the Ops team have the access to perform the steps suggested?
Usefulness — Is the content useful? For example, could someone determine the system’s purpose is and the business impact of the system breaking from the brief content provided in the System Description field?
Relevancy — Is the content still relevant or is it out of date? Do links to external content work as expected?
We were also helped by Jen Lambourne, the Head of Technical Writing at Government Digital Service, who delivered a brilliant talk for us in the week leading up to our Documentation Day. The talk was full of juicy content, but one thing it solidified for us was the value of task oriented content. In the case of our runbooks this was the troubleshooting section — providing a set of actionable, unambiguous steps for the Ops team to follow for each of the most likely to occur issues on a system, including what to do if those steps didn’t work.
On the back of all of this wonderful feedback we went away and worked on improving a single runbook to the Ops team’s specifications, if you’re in the FT you can see that runbook here. Happily, we got very positive feedback on our work and an SOS score for the runbook of 98%, We were getting there!
How to work most efficiently — the process
So now we knew what success looked like, we just had to make it as easy as possible for people to achieve in one day. We spent a *lot *of time on this in the run up to Documentation Day and that work was essential to the day being a success.
An early realisation we had was that some of the important fields in our runbooks would be the same for many of our systems (for example, Release Process and Failover Process). We spent time in advance writing shared documentation for these sections which could be linked to from all of the runbooks, saving people from individually writing content for these sections for each runbook on the day. Most importantly, abstracting this content away created a single source of truth which is easy to keep up to date.
We also created a detailed guide as a reference document for people on the day, explaining the sort of content that should be present in each runbook field, which fields are most important, and tips and tools for populating them. This, along with the example runbook we’d already written meant that that people had lots of guidance on what a great runbook should look like and how to get there.
Finally, we pulled all of this work together using Runbook.md.
Runbook.md
Runbook.md is a tool recently built by The Operations and Reliability team. It takes a runbook written in a Markdown file, extracts the relevant data, validates it, and imports it into the runbook database for presentation in the UI in the format used by the Ops team.
The primary benefit of Runbook.md to our teams was that it allowed us to move the contents of our runbooks from a standalone database to the repositories where the code for each system was stored. We’d had feedback from developers that having runbooks sit alongside code, like a README, would make them easier to find and maintain.
The huge benefit of this system for Documentation Day was that we were able to create a partly populated runbook file, in Markdown, for each Platinum system for people to edit on the day. These files could be updated by developers as the day progressed, and their content easily validated using the Runbook.md UI:
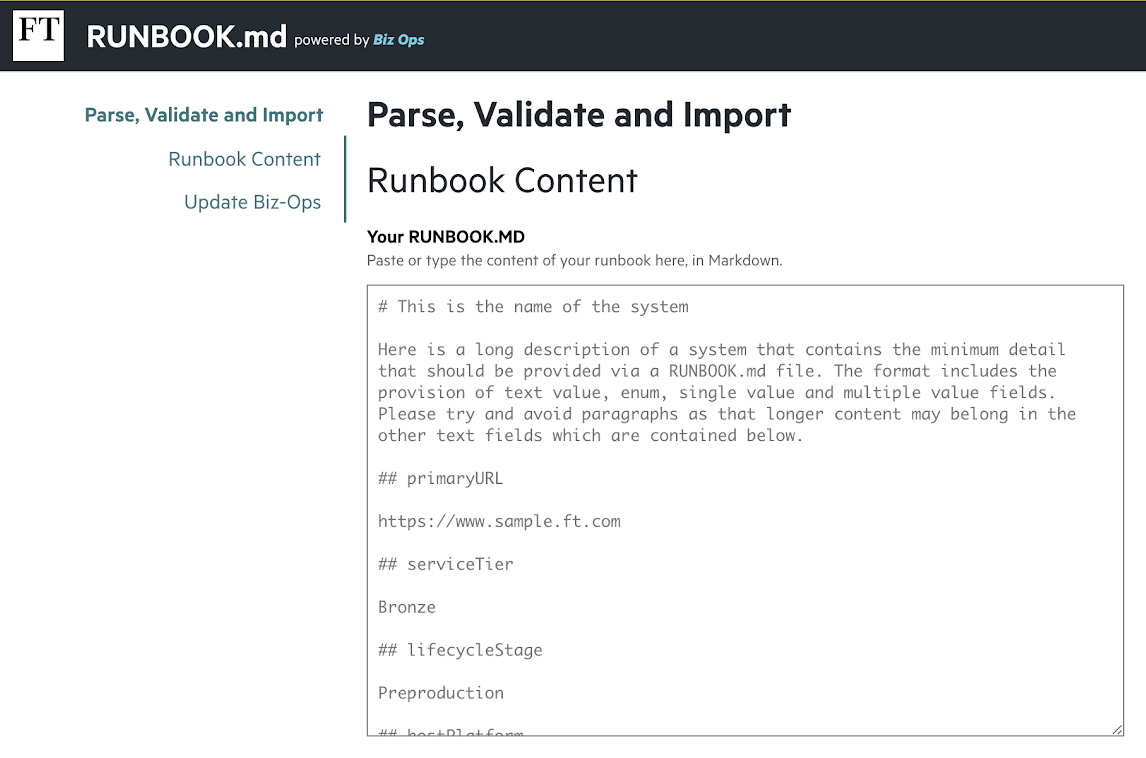 Runbook.md validation tool
Runbook.md validation tool
We pre-populated each runbook Markdown file with:
The content that already existed for the runbook in the current database, with a note to check its validity
Links in the relevant places to the external shared documentation that we’d created (e.g. for Failover Process)
Suggested content for some fields where known — particularly in the case of fields which had multiple choice options
Instructions and tips for filling out each field
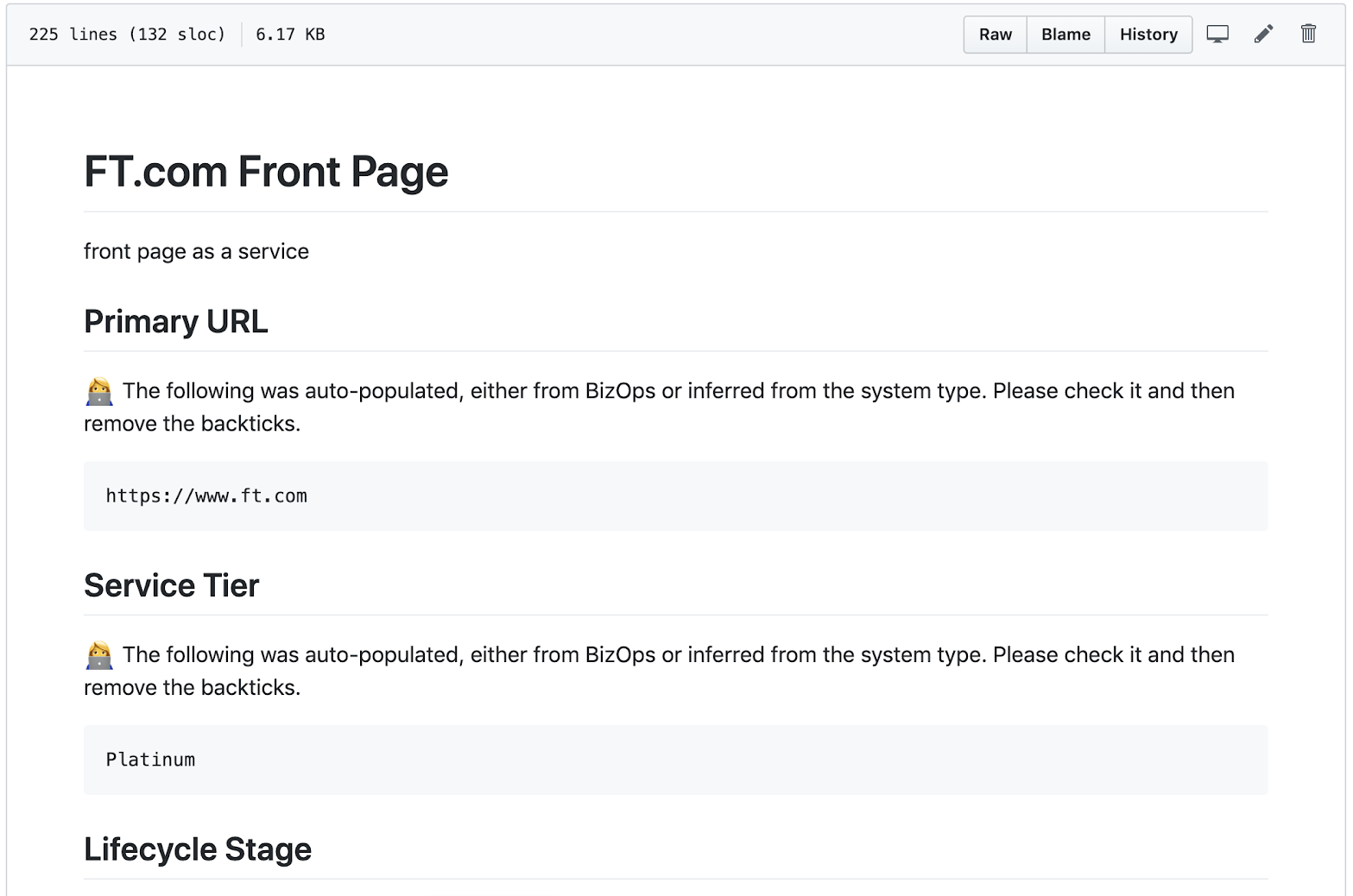 A runbook in markdown, with pre-populated content and tips
A runbook in markdown, with pre-populated content and tips
Creating this pre-filled runbook file for each system enabled people to start thinking about content (rather than process) as soon as Documentation Day began.
And providing all of these reference points within the file allowed people to start with the hardest questions first on the day—i.e. those things that need a bit of research and couldn’t be easily guessed — rather than taking time and cognitive effort thinking about the more straightforward content that we had already automated away with the work above.
Making it all work on the day

And so to the big day itself! By now we were confident we had the infrastructure in place for people to create great runbooks, but we also wanted participants to feel excited about the work, learn something new, and enjoy it. We put a few things in place on the day to make this happen:
A brief kick off session in the morning to bring everyone together, with the added bonus of pastries!
A shared space for people to work together during the day if they wanted
Participants working in teams of two that they chose — so they could get to know someone new if they wished, or rely on the support of a friend if they preferred
A dedicated Slack channel where people could talk during the day, discuss their progress, and ask for help from the wider team
Help on hand from the Operations & Reliability team to answer queries and iron out problems with the new process which kept things moving quickly and smoothly
A physical tracker on the wall — made of puppy stickers, of course — which everyone could add to during the day as their runbook scores increased
Prizes! Home made trophies, ready to be claimed by the best teams at the end of the day
 The Dogumentation-o-meter
The Dogumentation-o-meter
Everyone really got stuck in, and it was uplifting seeing people pair up with colleagues they didn’t know very well and learn new things about our systems. I asked some of the prize winners on the day what they felt they got out of it, and here’s what they had to say:
“I spend most of my time with systems I know fairly well so I really enjoyed delving into something I didn’t have much familiarity with and discovering quite how bad the runbook for it was — we split up tasks, worked out how various things like the backup process worked and documented as we went.”
“The tooling around runbook.md meant we could start actual work within about five minutes, and the ability to submit our content and see our scores creep up as we improved the docs kept me motivated throughout the day (gamification irritates me but it does work!)”.
Conversely(!)… “Updates we made ranged from drawing a new architecture diagram to hunting down monitoring status pages. All really interesting stuff, made all the more exhilarating by the SOS score — gamified documentation is the best kind of documentation.”
“I think we both learnt a hell of a lot about how the Operations team works and its definitions. One standout was the difference between changes and rollbacks vs failing over and failing back, failing back was not something I’d really considered as something to document but it makes so much sense in hindsight!”
“Initially it was a bit intimidating documenting an unknown part of FT.com, but working with someone else really made the experience a lot less frightening… A nice side effect of the day was that it led to updates of other code and READMEs to make the system as a whole more understandable. If you’re in the mindset of tidying, it kind of spreads to other things you touch.”
The outcome
We had a great day and our runbooks are in a much better state as a result — we’d increased our runbook SOS scores by an average of 25%, and all of the runbooks we worked on ended the day with an SOS score of 90% or higher. And there were some really nice secondary benefits that we found came out of the activity too.
Participants weren’t just documenting but learning how some of our poorly understood systems work, in many cases becoming the new experts on that service, even putting in fixes and making cost savings along the way. Put another way, Documentation Day was a great way to transfer knowledge to a wider group of people away from the few people that had a deep understanding of our systems, and because we were working in pairs the knowledge was shared even further.
We’ve also started sharing our learning with other programmes so they can replicate what we’ve done, and it’s great to see our preparation work being reused and the enthusiasm for improving documentation spreading throughout the wider Technology team.
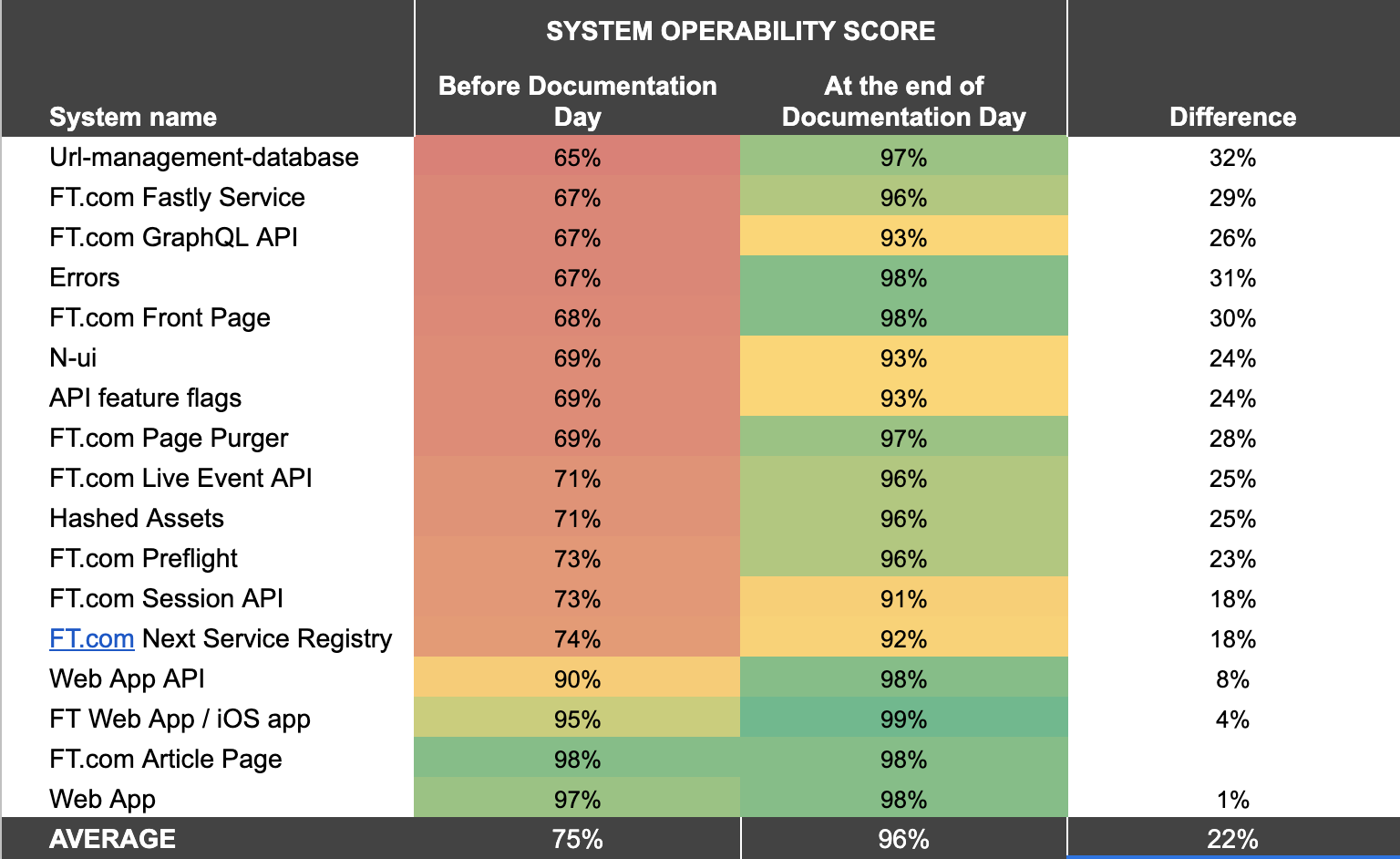 SOS scores for runbooks we worked on before and after Documentation Day
SOS scores for runbooks we worked on before and after Documentation Day
One thing that remains to be seen is whether we achieved our original aim of increasing the confidence of First and Second Line Support in fixing issues on our critical systems, as well as increasing the number of people volunteering to provide Second Line support. But it has only been a week so watch this space!
TL;DR — Takeaways to make documentation improvement a success:
Who are your audience, what do they need and how can you make sure you understand those needs?
Do you have content that will be repeated across your documentation? If so, can you abstract it away to create a single source of truth?
Task oriented content. Can you write your documentation in a way that it provides a set of actionable, unambiguous steps?
Understand what success looks like — can it be measured? Get quantitive as well as qualitative data if you can
Do a dry run — e.g. make one runbook really good and validate it in advance
How can you make the most of the time you have? Focus on the hard stuff and automate away the easy stuff if you can
Be really clear on the process and make it as easy as possible — cognitive load spent understanding process and logistics distracts away from the real value of answering hard questions
How can you make documentation easier to maintain after the initial push? e.g. in our case we moved our runbooks closer to our code
Thanks to Rhys Evans, Tatiana Stantonian, and Alice Bartlett for their help with this post.
And thanks to Rowan Beentje, Sam Parkinson, Tak Tran, Umberto Babini, and Rob Squires for providing their feedback from the day.